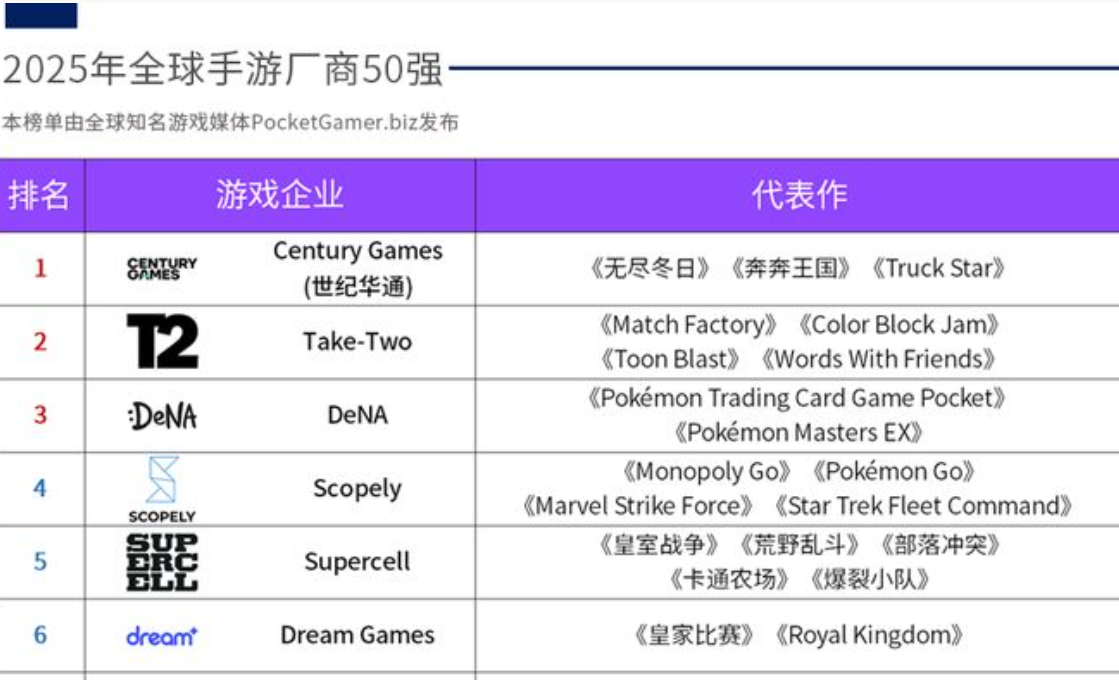
今天听完了Acquired.fm播客发布的《Google: The AI Company》完整音频,整整四个小时,信息密度极高,非常震撼。这期节目用25年的时间跨度,完整还原了Google如何汇聚全球最顶尖的AI人才、发明了Transformer这个改变世界的技术,却眼看着自己培养的人才创建OpenAI和Anthropic,最终陷入史上最经典的创新者困境。
听完后我整理了这份详细的编译,希望能帮你理解这个科技史上最引人入胜的案例。
史上最经典的创新者困境
想象这样一个场景:
你拥有一家极其赚钱的公司,在全球最大的市场之一中占据90%的份额,被美国政府认定为垄断企业。然后,你的研究实验室发明了一项革命性技术——这项技术比你现有的产品在大多数应用场景中都要好得多。
出于"纯粹的善意",你的科学家们将研究成果发表了出来。很快,创业公司们开始基于这项技术构建产品。
你会怎么做?当然是全力转向新技术,对吧?
但问题是:你还没有找到让这项新技术像旧业务那样赚钱的方法。
这就是今天的Google。
2017年,Google Brain团队发表了Transformer论文——这篇论文催生了OpenAI的ChatGPT、Anthropic、以及NVIDIA市值的暴涨。整个AI革命都建立在Google的这一项发明之上。
更令人惊讶的是:10年前,几乎所有AI领域的顶尖人才都在Google工作——Ilya Sutskever(OpenAI首席科学家)、Dario Amodei(Anthropic创始人)、Andrej Karpathy(前Tesla AI负责人)、Andrew Ng、所有DeepMind创始人...
这就像在计算机时代的黎明,IBM雇佣了全世界每一个会编程的人。
今天,Google依然拥有最好的AI资产组合:顶级模型Gemini、年收入500亿美元的云服务、唯一可与NVIDIA GPU抗衡的TPU芯片、以及全球最大的搜索流量入口。
但问题依然存在:Google应该如何抉择?是冒险全力投入AI,还是保护搜索广告这棵摇钱树?
让我们回到故事的起点,看看Google如何走到今天这一步。

关键时间线
第一章:起源(2000-2007)
微厨房里的对话改变了一切
故事要从2000年或2001年的某一天说起。
在Google的某个微厨房(micro kitchen)里,三个工程师正在吃午餐:Google最早的10名员工之一George Herrick、著名工程师Ben Gomes,以及新入职的Noam Shazeer。
George随口说了一句改变历史的话:
"我有个理论——压缩数据在技术上等同于理解数据。"
他的逻辑是:如果你能把一段信息压缩成更小的形式存储,然后再还原成原始形态,那么执行这个过程的系统一定"理解"了这些信息。就像学生学习教科书,在大脑中存储知识,然后通过考试证明理解了内容。
年轻的Noam Shazeer停下了手中的动作:"哇,如果这是真的,那太深刻了。"
这个想法预示了今天的大型语言模型——将全世界的知识压缩到几TB的参数中,然后"解压"还原出知识。
PHIL的诞生:第一个语言模型
接下来的几个月里,Noam和George做了一件最"Google"的事情:他们停下了所有其他工作,全身心投入研究这个想法。
这恰好是2001年Larry Page解雇了所有工程经理的时期——每个人都在做自己想做的事。
很多人觉得他们在浪费时间。但Sanjay Ghemawat(Jeff Dean的传奇搭档)说:"我觉得这很酷。"
George的回应令人印象深刻:"Sanjay认为这是好主意,而世界上没人比Sanjay更聪明,所以为什么要接受你认为这是坏主意的观点?"
他们深入研究自然语言的概率模型——对于互联网上出现的任何词序列,下一个词序列出现的概率是多少?(听起来是不是很熟悉?这就是今天LLM的基本原理。)
他们的第一个成果是Google搜索的"你是不是要找"拼写纠正功能”。
然后他们创建了一个相对"大型"(在当时)的语言模型,亲切地称之为PHIL(Probabilistic Hierarchical Inferential Learner,概率层次推理学习器)。
Jeff Dean的周末项目
2003年,Susan Wojcicki和Jeff Dean准备推出AdSense。他们需要理解第三方网页的内容,以便投放相关广告。
Jeff Dean借用了PHIL,用一周时间写出了AdSense的实现(因为他是Jeff Dean)。
Boom,AdSense诞生了。这为Google一夜之间带来了数十亿美元的新收入——因为他们把原有的AdWords广告投放到了第三方网页上,瞬间扩大了库存。
Jeff Dean传奇时刻
在那个"Chuck Norris Facts"流行的年代,Google内部流行起了"Jeff Dean Facts":
真空中的光速曾经是每小时35英里,直到Jeff Dean花了一个周末优化了物理学。
Jeff Dean的PIN码是圆周率的最后四位数字。
对Jeff Dean来说,NP问题意味着"No Problemo"(没问题)。
到2000年代中期,PHIL已经占用了Google数据中心15%的基础设施——用于AdSense广告投放、拼写纠正等各种应用。
第二章:黄金十年(2007-2012)
从12小时到100毫秒的奇迹
2007年,Google推出了翻译产品。首席架构师Franz Och参加了DARPA(美国国防高级研究计划局)的机器翻译挑战赛。
Franz构建了一个更大的语言模型,在两万亿词的Google搜索索引上训练,取得了天文数字般的高分。
Jeff Dean听说后问:"太棒了!你们什么时候上线?"
Franz回答:"Jeff,你不明白。这是研究项目,不是产品。这个模型翻译一个句子需要12小时。"
DARPA挑战赛的规则是:周一给你一组句子,周五提交翻译结果。所以他们有足够时间让服务器运行。
Jeff Dean的回应是:"让我看看你的代码。"
几个月后,Jeff重新架构了算法,让它可以并行处理句子和单词。因为翻译时不一定需要按顺序处理——可以把问题分解成独立的部分。
而Google的基础设施(Jeff和Sanjay基本上参与构建了)极其擅长并行化——可以把工作负载分解成小块,发送到各个数据中心,然后重新组装返回给用户。
结果:平均翻译时间从12小时降到了100毫秒。
然后他们在Google翻译中上线了这个模型,效果惊人。
这是Google在产品中使用的 第一个"大型"语言模型 。
斯坦福AI实验室的秘密
2007年4月,Larry Page从斯坦福挖来了Sebastian Thrun——斯坦福人工智能实验室(SAIL)的负责人。
有趣的是,Sebastian几乎是被"收购"进来的——他和几个研究生正在创业,已经拿到了Benchmark和Sequoia的term sheet。Larry直接说:"不如我们用签字费的形式收购你们还未成立的公司?"
SAIL不仅汇聚了世界上最优秀的AI教授,还有一批斯坦福本科生在那里做研究助理。
其中一位是Meta的首席产品官 Chris Cox 。
另一位大一大二学生后来辍学了,参加了YC 2005年夏季第一批,创办了一个失败的本地移动社交网络...
那就是Sam Altman,公司叫Loopt。
是的,Sam Altman曾在SAIL做研究,还在WWDC上和乔布斯同台展示,穿着双层翻领衬衫——那是不同的科技时代。
Google X与Google Brain的诞生
Sebastian加入Google后,首个项目是 Ground Truth ——重新创建所有地图数据,摆脱对Tele Atlas和Navtech的依赖。
这个项目非常成功。Sebastian开始游说Larry和Sergey:
"我们应该大规模做这件事——把AI教授们引入Google做兼职。他们可以保留学术职位,来这里参与项目。他们会喜欢的——看到自己的工作被数百万人使用,赚钱,拿股票,还能继续当教授。"
Win-win-win。
2007年12月,Sebastian邀请多伦多大学一位相对不知名的机器学习教授Geoff Hinton来Google做技术演讲——谈谈他和学生们在神经网络方面的新工作。
Geoff Hinton,现在被称为"神经网络教父",在当时是边缘学者。 神经网络不受尊重——30-40年前的炒作已经破灭。
有趣的冷知识:Geoff Hinton是 George Boole的曾曾孙 ——布尔代数和布尔逻辑的发明者。讽刺的是,布尔逻辑是符号化、确定性的计算机科学基础,而神经网络恰恰相反——是非确定性的。
Geoff和前博士后Yann LeCun一直在传播:如果我们能实现多层深度神经网络(深度学习),就能实现这个领域的承诺。
到2007年,摩尔定律的发展让测试这些理论成为可能。
Geoff的演讲在Google引发轰动——这可以让他们的语言模型工作得更好。Sebastian把Geoff引入Google,先是顾问,后来Geoff在2011-2012年左右成为Google的 暑期实习生 ——当时他已经60岁了。
到2009年末,Sebastian、Larry和Sergey决定成立一个新部门:Google X,登月工厂。
第一个项目Sebastian自己领导(我们稍后再说)。
第二个项目将改变整个世界——Google Brain。
Google Brain:Distbelief与猫论文
Andrew Ng接任SAIL负责人后,也被Sebastian招募来兼职。
2010-2011年间的某天,Andrew在Google园区碰到了Jeff Dean。他们讨论了语言模型和Geoff Hinton的深度学习工作。
他们决定:是时候在Google高度并行化的基础设施上,尝试构建一个真正大型的深度学习模型了。
2011年,Andrew Ng、Jeff Dean和神经科学博士Greg Corrado三人启动了Google X的第二个官方项目: Google Brain 。
Jeff为此构建了一个系统,命名为 Distbelief ——既是双关"分布式"(distributed),也是"难以置信"(disbelief),因为大多数人认为这不会成功。
技术突破:异步分布式学习
当时所有研究都认为需要 同步 训练——所有计算需要密集地在单机上进行,就像GPU那样。
但Jeff Dean反其道而行之:Distbelief在大量CPU核心上分布式运行,可能跨越整个数据中心,甚至不同数据中心。
理论上这很糟糕——每台机器都需要等待其他机器同步参数。
但Distbelief采用 异步更新 ——不等待最新参数,基于过时数据更新。
理论上不应该有效。但它成功了。
改变世界的猫论文
2011年底,他们提交了一篇论文:《使用大规模无监督学习构建高级特征》——但所有人都叫它 "猫论文"(Cat Paper) 。
他们训练了一个九层神经网络,使用16,000个CPU核心(跨1000台机器),从YouTube视频的未标注帧中识别猫。
Sundar Pichai后来回忆说,看到猫论文是他在Google历史上最关键的时刻之一。
后来的TGIF(全员大会)上展示这个结果时,所有Google员工都意识到:"天啊,一切都变了。"
猫论文的商业影响
Jeff Dean的描述:
"我们构建的系统在1000万个随机YouTube帧上进行无监督学习。经过一段时间训练后,模型在最高层构建了一个表示—— 有一个神经元会对猫的图像兴奋。它从未被告知什么是猫,但它见过足够多的猫正面照片,那个神经元就会为猫点亮,基本不为其他东西点亮。 "

这证明了:大型神经网络可以在没有监督、没有标注数据的情况下学习有意义的模式。
而且可以在Google自己构建的分布式系统上运行。
YouTube的问题是: 人们上传视频,但不擅长描述视频内容。推荐系统只能基于标题和描述。
猫论文证明,可以用深度神经网络"看懂"视频内部的内容,然后用这些数据决定推荐什么视频。
这导致了YouTube的一切。 让YouTube走上了成为全球最大互联网资产和最大媒体公司的道路。
从2012年到2022年ChatGPT发布,AI已经在塑造我们所有人的存在,驱动着数千亿美元的收入。
它在YouTube feed中,然后Facebook借鉴了(他们雇佣Yann LeCun成立Facebook AI Research),然后到Instagram,然后TikTok和字节跳动采用,然后回到Facebook和YouTube的Reels和Shorts。
这是接下来10年人类在地球上度过闲暇时间的主要方式。
重要观点:AI时代始于2012年
所有人都说2022年后是AI时代。但对于任何能充分利用推荐系统和分类系统的公司来说,AI时代始于2012年。
第三章:大爆炸时刻(2012-2017)
AlexNet:深度学习的"宇宙大爆炸"
2012年,除了猫论文,还有Jensen(NVIDIA CEO)所说的"AI大爆炸时刻": AlexNet 。
回到多伦多大学,Geoff Hinton有两个研究生:Alex Krizhevsky和 Ilya Sutskever (未来OpenAI的联合创始人和首席科学家)。
三人用Geoff的深度神经网络算法参加著名的 ImageNet竞赛 ——斯坦福李飞飞组织的年度机器视觉算法竞赛。
李飞飞组建了1400万张手工标注图像的数据库(用Amazon Mechanical Turk标注)。
竞赛内容是:哪个团队能写出算法,在不看标签的情况下——仅看图像——最准确地预测标签?
GPU的关键作用
多伦多团队去本地百思买(Best Buy)买了两块 NVIDIA GeForce GTX 580显卡 ——当时NVIDIA的顶级游戏卡。
他们用NVIDIA的编程语言CUDA重写神经网络算法,在这两块现成的GTX 580上训练。
结果:他们比任何其他参赛者好40%。
这就是AlexNet——引发深度学习革命的时刻。
第一次AI拍卖
三人做了很自然的事:成立公司 DNN Research(Deep Neural Network Research) 。
这家公司没有产品。只有AI研究人员。
可以预见的是,它几乎立即被收购了——但有个有趣的故事:
第一个出价的实际上是 百度 。Geoff Hinton做了任何学者都会做的事来确定公司的市场价值:
"非常感谢。我现在要举办一场拍卖。"
他联系了百度、Google、微软和DeepMind。拍卖以 4400万美元 结束, Google赢得 。团队直接加入Google Brain。
几年后,负责Google X的Astro Teller在《纽约时报》上被引用说:
"Google Brain为Google核心业务(搜索、广告、YouTube)带来的收益,已经远超Google X和整个公司多年来所有其他投资的总和。"
DeepMind:AI界的YouTube收购
但Google的AI故事还有另一个重要部分——一次外部收购,相当于Google AI领域的YouTube收购: DeepMind 。
2014年1月,Google花5.5亿美元收购了一家伦敦的不知名AI公司。人们困惑:Google在伦敦买了个我从未听说过的做AI的东西?
事实证明,这次收购是蝴蝶煽动翅膀的时刻,直接导致了OpenAI、ChatGPT、Anthropic,基本上导致了一切。
DeepMind的起源
DeepMind成立于2010年,由神经科学博士 Demis Hassabis (之前创办过视频游戏公司)、伦敦大学学院的 Shane Legg ,以及第三位联合创始人 Mustafa Suleyman 共同创立。
公司标语:"解决智能,然后用它解决一切。"
Founders Fund领投了约200万美元的种子轮。后来Elon Musk也成为投资人(经过一次关于AI风险和火星的对话)。
收购大战
2013年底,Mark Zuckerberg打电话来要收购。但Demis坚持要独立性和特定的治理结构,Facebook不同意。
Elon Musk提出用特斯拉股票收购,但希望他们为特斯拉工作,这不符合DeepMind的愿景。
Larry Page(据说在和Elon的飞机上)得知此事,与Demis建立了联系。Demis感觉Larry理解使命。
经过谈判,Google提供 5.5亿美元 ,交易达成,建立了独立的伦理委员会(包括PayPal黑帮的Reid Hoffman)。DeepMind团队保持独立,专注于AGI研究。
收购后进展顺利,包括大幅节省运营成本(数据中心冷却降低40%能耗),后来的AlphaGo震惊世界。
第四章:Transformer革命(2017)
改变一切的八人团队
2017年,Google Brain团队的八名研究人员发表了一篇论文。
Google本身的反应是:"酷。这是我们语言模型工作的下一次迭代。很好。"
但这篇论文和它的发表,实际上给了OpenAI机会——接过球并奔跑,构建下一个Google。
因为这是Transformer论文。
从RNN到Transformer的演进
在Transformer论文之前,Google已经用神经网络重写了翻译系统,基于 循环神经网络(RNN) 和 LSTM ——当时的最先进技术,是巨大进步。
但持续研究发现了局限性——特别是一个大问题:它们太快"遗忘"上下文。
Google Brain内部团队开始寻找更好的架构,既能像LSTM那样不会太快忘记上下文,又能更好地并行化和扩展。
研究员 Jakob Uszkoreit 一直在探索拓宽语言处理中"注意力"(attention)范围的想法。
如果不只关注紧邻的词,而是告诉模型:注意整个文本语料库会怎样?
Jakob开始合作,他们决定把这个新技术称为 Transformer 。
Noam Shazeer的魔法
还记得Noam Shazeer吗?早期语言模型PHIL的创造者,AdSense的关键人物。
Noam听说这个项目后说:"嘿,我在这方面有经验。听起来很酷。LSTM确实有问题。这可能有前途。我要加入。"
在Noam加入之前,他们有Transformer的工作实现,但实际上没有比LSTM产生更好的结果。
Noam加入团队,基本上"pull了一个Jeff Dean"—— 从头重写了整个代码库 。
完成后,Transformer现在 碾压 了基于LSTM的Google翻译解决方案。
而且他们发现:模型越大,结果越好。
他们发表了论文: 《Attention Is All You Need》 (注意力就是你所需要的一切)——明显呼应披头士经典歌曲。
Transformer产生最先进的结果,极其高效,成为GPT等的基础。
截至2025年,这篇论文被引用超过173,000次,是21世纪被引用第7多的论文。
人才流失的开始
当然,在几年内,Transformer论文的全部八位作者都离开了Google,要么创办要么加入AI创业公司,包括OpenAI。
残酷。
第五章:OpenAI的崛起(2018-2022)
GPT系列的诞生
2018年6月,OpenAI发表了一篇论文,描述他们如何采用Transformer,开发了一种新方法:
在互联网大量通用文本上预训练
然后将这种通用预训练 微调 到特定用例
他们还宣布训练并运行了这种方法的第一个概念验证模型: GPT-1(Generatively Pre-trained Transformer version 1) 。
2019年,在第一次微软合作和10亿美元投资后,OpenAI发布 GPT-2 ——仍然早期但非常有前途。
2020年6月, GPT-3 问世。仍然没有面向用户的前端界面,但已经非常好。开始出现大量炒作。
之后,微软再投资 20亿美元 。
2021年夏天,微软使用GPT-3发布 GitHub Copilot ——这是第一个,不仅是微软产品,而是任何地方第一个将GPT融入的产品。
ChatGPT:改变游戏规则的时刻
到2022年底,OpenAI有了GPT-3.5。但仍有个问题:我该如何实际使用它?
Sam Altman说:我们应该做一个聊天机器人。这似乎是自然的界面。
一周内,内部就做出来了。他们只是把对ChatGPT 3.5 API的调用变成一个产品——你和它聊天,每次发送消息就调用GPT-3.5 API。
结果证明这是神奇的产品。
2022年11月30日,OpenAI推出GPT-3.5新界面的研究预览版: ChatGPT 。
那天早上,Sam Altman发推:"今天我们推出了ChatGPT。试试和它聊天:chat.openai.com"
不到一周:100万用户
一个月后(12月31日):3000万用户
两个月后(1月底):1亿注册用户——史上达到这一里程碑最快的产品
完全疯狂。
第六章:Google的Code Red(2023-2025)
错失的机会
讽刺的是,在ChatGPT之前,Google就有聊天机器人。
Noam Shazeer——那个不可思议的工程师,重新架构了Transformer,Transformer论文的主要作者之一,在Google拥有传奇职业生涯——在Transformer论文发表后立即开始向Google领导层倡议:
"我认为Transformer将如此重大,我们应该考虑抛弃搜索索引和10个蓝色链接模型,全力将整个Google转变为一个巨大的Transformer模型。"
Noam实际上构建了一个大型Transformer模型的聊天机器人界面。
Google继续研究Mina项目,发展成 Lambda ——也是聊天机器人,也是内部的。
2022年5月,他们发布了向公众开放的 AI Test Kitchen ——一个AI产品测试区,人们可以试用Google的内部AI产品,包括Lambda聊天界面。
但有个限制:Google将Lambda Chat的对话限制在五轮。 五轮后,就结束了。谢谢。再见。
原因是:安全考虑。
存在威胁时刻
ChatGPT问世,成为史上最快达到1亿用户的产品。
对Sundar、Larry、Sergey、所有Google领导层来说,立即显而易见:这是对Google的存在威胁。
ChatGPT是做Google搜索同样工作的更好用户体验。
2022年12月,甚至在大规模推出之前但在ChatGPT时刻之后,Sundar在公司内部发布了Code Red(红色警报)。
Bard的灾难性发布
第一件事:他们把Lambda模型和聊天机器人界面拿出来,重新品牌为 Bard 。
2023年2月,立即发布,向所有人开放。
也许这是正确的举动,但天啊,这是个糟糕的产品。
很明显它缺少ChatGPT拥有的某种魔力——用人类反馈进行强化学习(RLHF)来真正调整响应的适当性、语气、声音、正确性。
更糟糕的是:在Bard的发布视频中——一个精心编排的预录视频——Bard对其中一个查询给出了不准确的事实回应。
Google股价单日暴跌8%,市值蒸发1000亿美元。
5月,他们用Brain团队的新模型 PaLM 替换Lambda。稍好一点,但仍然明显落后于GPT-3.5。
而且2023年3月,OpenAI推出了 GPT-4 ——更好。
第七章:Gemini时代(2023至今)
Sundar的两个重大决策
此时,Sundar做出了两个非常非常重大的决定:
决策一:统一AI团队
"我们不能再在Google内部有两个AI团队。我们要把Brain和DeepMind合并为一个实体:Google DeepMind。"
Demis Hassabis担任CEO,Jeff Dean继续担任首席科学家。
决策二:一个模型统治一切
"我要你们去做一个新模型,我们只有一个模型。这将是Google所有内部使用、所有外部AI产品的模型。它将被称为Gemini。不再有不同的模型,不再有不同的团队。只有一个模型用于一切。"
这也是巨大的决定。
Gemini的快速发展
Jeff Dean和Brain的Oriol Vinyals与DeepMind团队合作,开始研究Gemini。
后来当他们通过Character AI交易把Noam带回来时,Noam加入Gemini团队。现在Jeff和Noam是Gemini的两位联合技术负责人。
关键特性:Gemini将是多模态的——文本、图像、视频、音频,一个模型。
时间线:
2023年5月:在Google I/O主题演讲中宣布Gemini计划
2023年12月:早期公开访问
2024年2月:推出Gemini 1.5,具有100万token上下文窗口
2025年2月:发布Gemini 2.0
2025年3月:一个月后推出Gemini 2.5 Pro实验模式
2025年6月:GA(全面可用)
六个月构建、训练、发布。疯狂。
他们宣布Gemini现在有 4.5亿月活跃用户 。
AI全面整合
AI Overviews(搜索AI概览):首先作为Labs产品推出,后来成为所有使用Google搜索的人的标准
AI Mode:深度AI搜索模式
多模态生成工具:Veo(视频)、Genie(游戏)等
企业应用:Google Workspace全面AI化
第八章:创新者困境
Bull Case(乐观情景):Google的优势
1. 无与伦比的分发渠道
依然是全球"互联网入口"
可以随意引导流量(AI Overviews、AI Mode)
Google搜索流量仍处于历史高位
2. 全栈AI能力(独一无二)
顶级模型:Gemini
自研芯片:TPU(唯一可与NVIDIA GPU抗衡的规模化AI芯片)
云基础设施:Google Cloud(年收入500亿美元)
自给自足的资金:不依赖外部融资
有人告诉我:如果你没有基础前沿模型或AI芯片,你在AI市场可能只是商品。Google是唯一两者都有的公司。
3. 基础设施优势
私有数据中心间光纤网络
定制化硬件架构
无人能及的规模
4. 数据与个性化潜力
海量个人和企业数据
可能实现深度个性化AI
1.5亿Google One付费用户且快速增长
5. 新市场机会
Waymo自动驾驶
视频AI
企业AI解决方案
远超传统搜索的应用边界
6. 唯一自给自足的模型制造商
云厂商有自给自足的资金,NVIDIA有,但所有模型制造商都依赖外部资本——除了Google。
Bear Case(悲观情景):巨大挑战
1. 变现难题
AI产品形态不适合广告
价值创造多,价值捕获少
Google在美国每用户每年赚约400美元(搜索广告)
谁会为AI付费400美元/年?只有很小一部分人
2. 市场份额下降
搜索市场占90%
AI市场占多少?可能只有25%,最多50%
不再是主导者
3. 高价值场景流失
AI正在蚕食最有价值的搜索场景
旅行规划?现在用AI
不再点击Expedia的广告
4. 产品优势不明显
1998年Google推出时立即明显是最优产品
今天绝对不是这样
有4-5个同等优秀的AI产品
Bard初版明显劣质,现在只是"追平"
5. 失去生态支持
现在是在位者,不再是挑战者
人们和生态系统不再像Google创业时那样为它加油
也不像移动转型时那样
6. 人才流失
Transformer八位作者全部离开
顶级AI人才持续流向OpenAI、Anthropic等
创业公司吸引力更大
战略困境的本质
播客的核心观点:
"这是有史以来最引人入胜的创新者困境案例。"
Larry和Sergey控制着公司。他们多次被引用说宁愿破产也不愿在AI上失败。
但他们真的会吗?
如果AI不像搜索那样是个好生意——虽然感觉当然会是,当然必须是;仅仅因为它创造的巨大价值——如果不是,他们在两个结果之间选择:
实现我们的使命:组织世界信息,使其普遍可访问和有用
拥有世界上最赚钱的科技公司
哪一个会赢?
因为如果只是使命,他们应该在AI模式上比现在激进得多,完全转向Gemini。
这是一根非常难以穿过的针。
第九章:未来展望
Google正在做对的事情
"如果看所有大型科技公司,Google——尽管事情的开始看起来多么不太可能——可能是目前在AI上尝试穿针引线做得最好的。"
"这对Sundar和他们的领导层来说令人难以置信地值得赞扬。"
他们在做艰难的决定:
统一DeepMind和Brain
整合并标准化为一个模型
快速发布产品
同时不做鲁莽的决定
"快速但不鲁莽(Rapid but not rash)。"
战略建议
1. 继续大胆整合
坚持Gemini统一战略
保持快速迭代节奏
不要因短期压力动摇
2. 探索新变现模式
AI广告新形式
个性化服务付费
企业解决方案深化
3. 激活创新文化
保持工程师创新DNA
延续"宁愿舍利润也不输AI"的初心
鼓励内部实验和冒险
4. 利用全栈优势
硬件+模型+数据+分发的闭环
构建AI时代的平台终局
基础设施领先性转化为产品优势
5. 务实预期管理
不再追求"独占性市场"
凭借规模优势仍可长期胜出
接受多极竞争的新常态
6. 主动预判风险
警惕"温水煮青蛙"
持续监控AI替代搜索的进度
战略创新而非被动应对
一个时代的轮回
25年前,Larry Page说:
"人工智能将是Google的终极版本。如果我们有终极搜索引擎,它将理解网络上的一切,理解你想要什么,并给你正确的东西。这显然是人工智能。我们现在还远未做到。但我们可以逐步接近,这基本上就是我们在这里工作的内容。"
那是2000年。
今天,Google拥有世界上最好的AI模型之一、最强的AI芯片、最大规模的云基础设施、以及数十亿用户的分发渠道。
但他们也面临着有史以来最经典的创新者困境:
发明了改变世界的技术(Transformer)
看着自己培养的人才创建竞争对手(OpenAI、Anthropic)
拥有最好的资源却被自己的成功束缚
必须在保护现金牛和拥抱未来之间做出选择
这将是商业史上最引人入胜的案例研究之一。
Google能否成功穿过这根针?
能否在不牺牲搜索业务的情况下赢得AI时代?
能否证明在位者也可以主导下一个时代?
答案将在接下来几年揭晓。
而无论结果如何,Google AI编年史已经告诉我们:
有时候,发明未来和拥有未来,是两件截然不同的事。
关键时间线

核心人物

lovart制图
技术里程碑解释

lovart制图